A few years ago, I put together a fun little app that used node.js, service bus, cloud services, and the Instagram realtime API to build a realtime visualization of images posted to Instagram. In 2 years time, a lot has changed on the Azure platform. I decided to go back into that code, and retool it to take advantage of some new technology and platform features. And for fun.
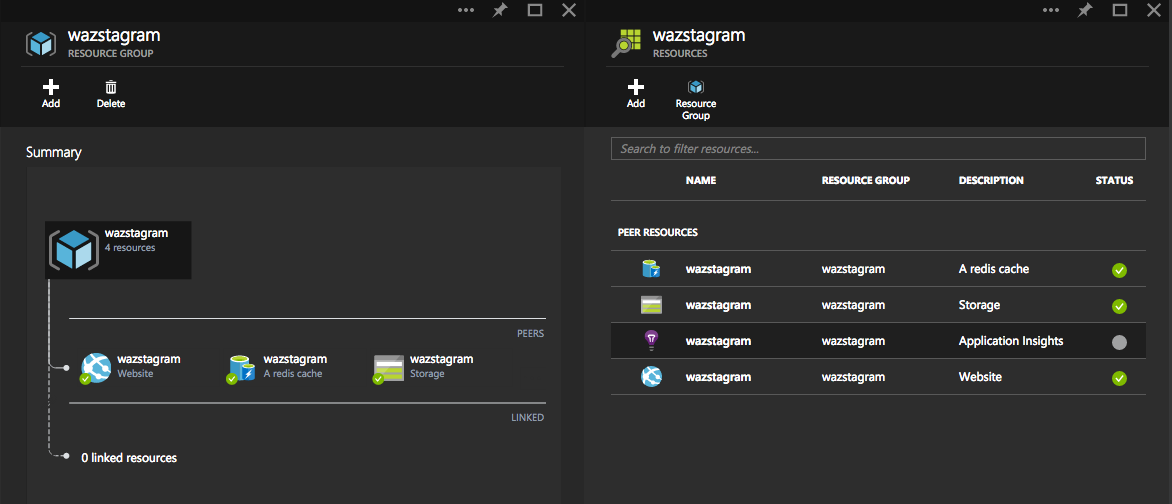
I’m using resource groups to organize the various services. Resource groups provide a nice way to visualize and manage the services that make up an app. RBAC and aggregated monitoring are two of the biggest features that make this useful.
Websites & Websockets
In the original version of this app, I chose to use cloud services instead of Azure web sites. One of the biggest reasons for this choice was websocket support with socket.io. At the time, Azure websites did not support websockets. Well… now it does. There are a lot of reasons to choose websites over cloud services:
Fast continuous deployment via Github
Low concept count, no special tooling needed
Now supports deployment slots, ssl, enterprise features
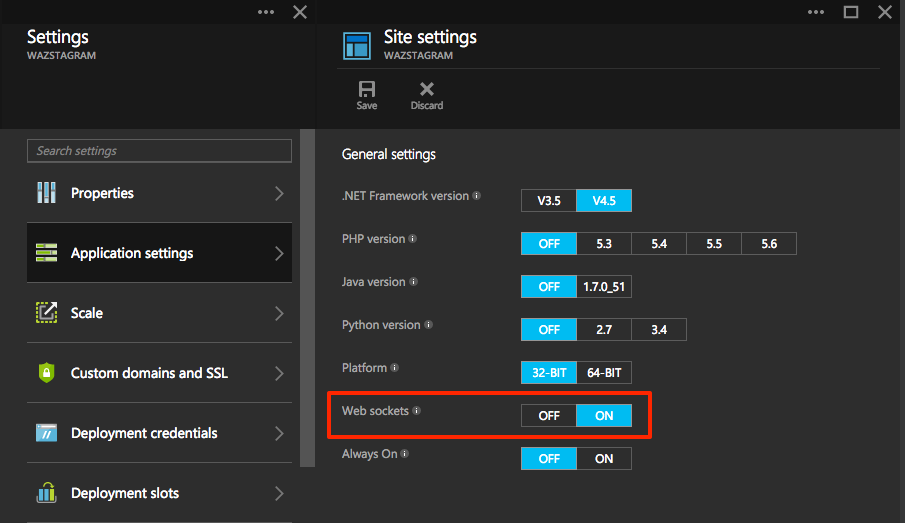
When you create your site, make sure to turn on websockets:
io.js
io.js is a fork of node.js that provides a faster release cycle and es6 support. It’s pretty easy to get it running on Azure, thanks to iojs-azure. Just to prove I’m running io.js instead of node.js, I added this little bit in my server.js:
logger.info(`Started wazstagram running on ${process.title}${process.version}`,);
The results:
redis
In the previous version of this app, I used service bus for publishing messages from the back end process to the scaled out front end nodes. This worked great, but I’m more comfortable with redis. There are a lot of options for redis on Azure, but we recently rolled out a first class redis cache service, so I decided to give that a try. I’m really looking to use two features from redis:
Pub / Sub - Messages received by Instagram are published to the scaled out front end
Caching - I keep a cache of 100 messages around to auto-fill the page on the initial visit
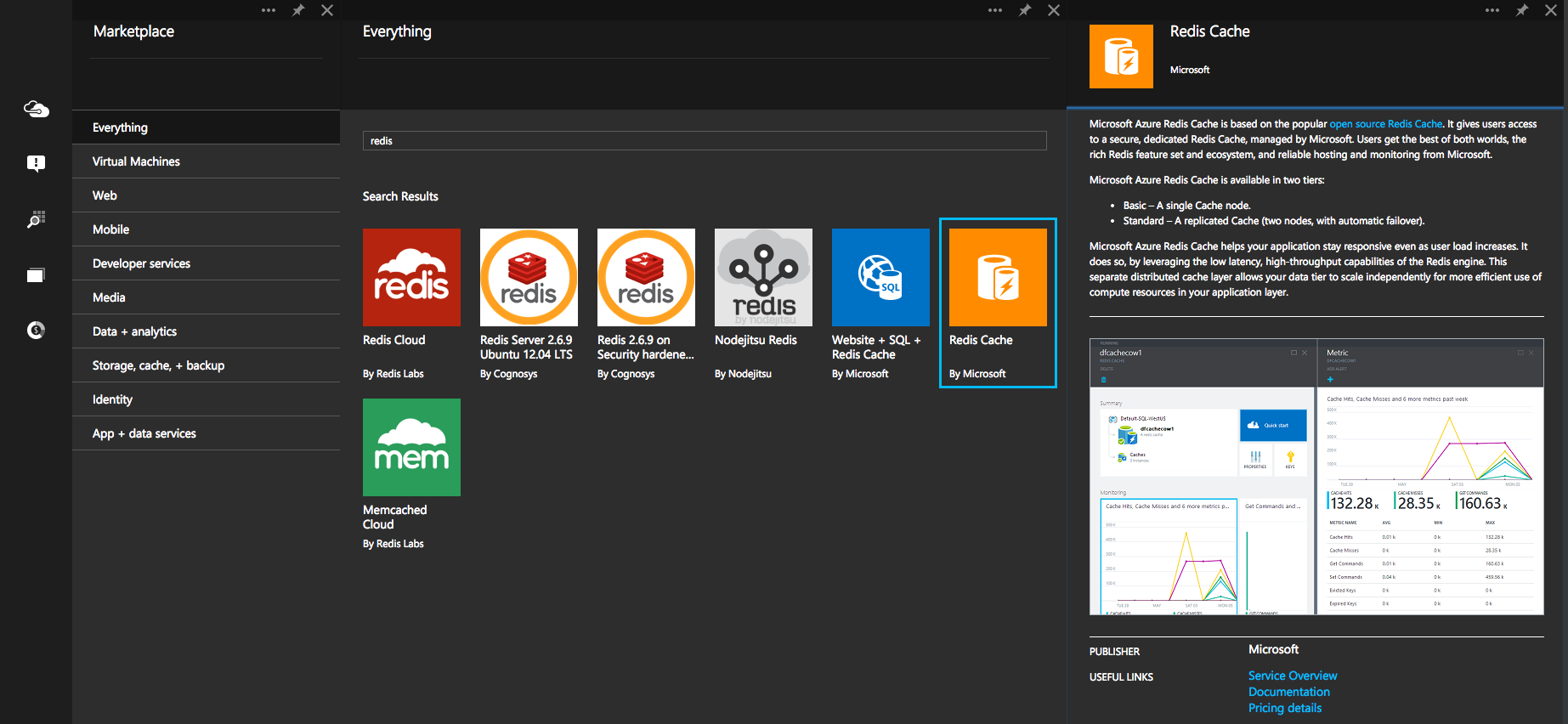
You can create a new redis cache from the Gallery:
After creating the cache, you have a good ol standard redis database. Nothing special/fancy/funky. You can connect to it using the standard redis-cli from the command line:
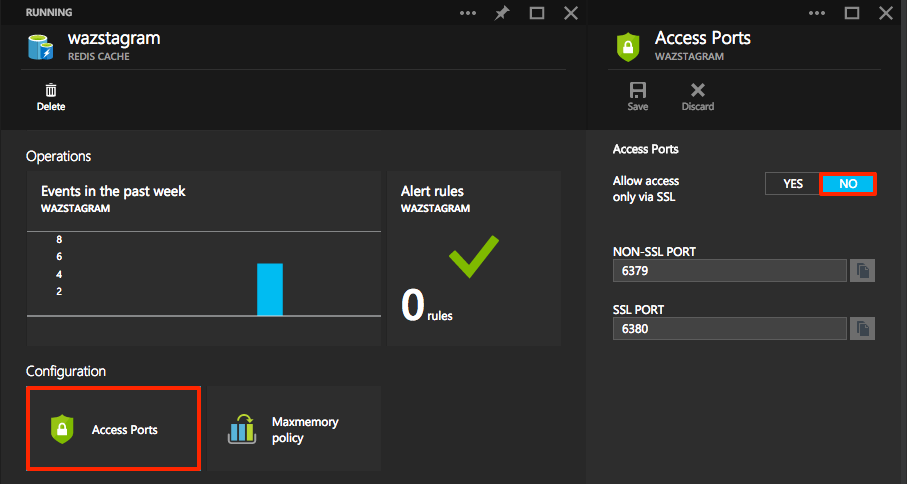
Note the password I’m using is actually one of the management keys provided in the portal. I also chose to disable SSL, as nothing I’m storing is sensitive data:
I used node-redis to talk to the database, both for pub/sub and cache. First, create a new redis client:
functioncreateRedisClient(){returnredis.createClient(6379,nconf.get("redisHost"),{auth_pass:nconf.get("redisKey"),return_buffers:true,}).on("error",function(err){logger.error("ERR:REDIS: "+err);});}// create redis clients for the publisher and the subscribervarredisSubClient=createRedisClient();varredisPubClient=createRedisClient();
PROTIP: Use nconf to store secrets in json locally, and read from app settings in Azure.
When the Instagram API sends a new image, it’s published to a channel, and centrally cached:
logger.verbose("new pic published from: "+message.city);logger.verbose(message.pic);redisPubClient.publish("pics",JSON.stringify(message));// cache results to ensure users get an initial blast of (n) images per cityredisPubClient.lpush(message.city,message.pic);redisPubClient.ltrim(message.city,0,100);redisPubClient.lpush(universe,message.pic);redisPubClient.ltrim(universe,0,100);
The centralized cache is great, since I don’t need to use up memory in each io.js process used in my site (keep scale out in mind). Each client also connects to the pub/sub channel, ensuring every instance gets new messages:
// listen to new images from redis pub/subredisSubClient.on("message",function(channel,message){logger.verbose("channel: "+channel+" ; message: "+message);varm=JSON.parse(message.toString());io.sockets.in(m.city).emit("newPic",m.pic);io.sockets.in(universe).emit("newPic",m.pic);}).subscribe("pics");
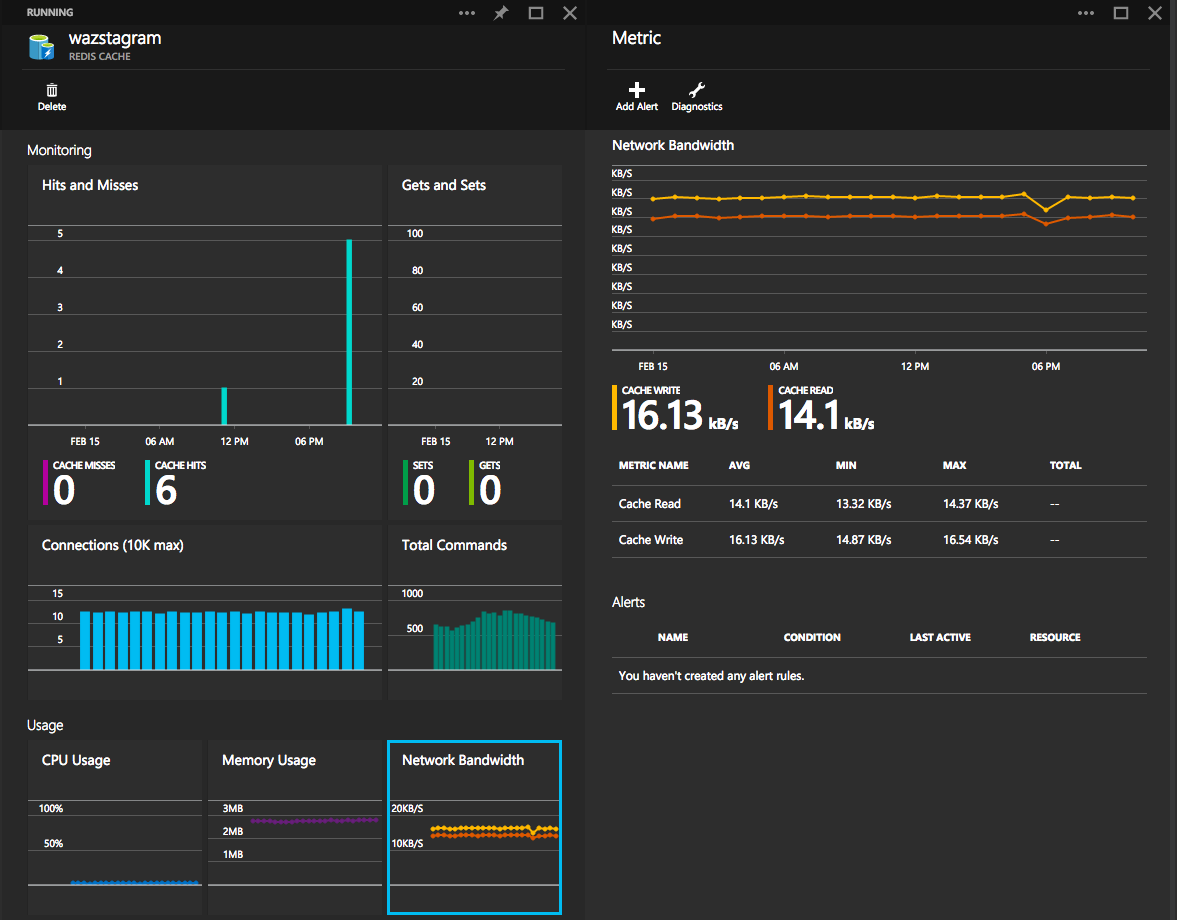
After setting up the service, I was using the redis-cli to do a lot of debugging. There’s also some great monitoring/metrics/alerts available in the portal:
A few weeks ago I got pulled into a meeting. There’s another team at Microsoft that’s using our SDK to build their UI, and they had a few questions. Their devs had a chance to get their hands on our SDK, and like most product guys, I was interested in getting some unfiltered feedback from an internal team. Before getting into details, someone dropped the phrase “Please don’t take this personally, but…“
The feedback that comes after that sentence is really important. We write it down. We share it with the team. We stack it up against other priorities, compare it with feedback from teams who have similar pain points, and use it to find a way to make our product better. Customer feedback (from an internal team or external customer) is so incredibly critical, that any product team has a similar pattern/process for dealing with it. So what’s the problem?
Any feedback that starts with “Don’t take this personally” really pisses me off. When you say this to someone, you’re making one of two judgments about this person:
They are not personally invested in their work. They go to their job, they do whatever work is put in front of them, and then they go home. If what they’ve made is not good, it doesn’t bother them.
They are personally invested in their work. They want to create something amazing, and will go to great lengths to do so. Whatever you’re about to say - despite your warning - They’re going to take it personally.
For me, that expression elicits a sort of Marty Mcfly “nobody calls me chicken” response.
What’s more personal to me than my product!? I work at Microsoft because I genuinely believe it’s the best place for me to build stuff that has a real tangible impact. I went through years of school so I could do *this*. I moved my family moved across the country. I work 50-60 hours a week (probably more than I should) because I wanted to build *this*. My product is in many ways a reflection of me. What could possibly be more personal?
Does this mean I don’t want criticism? Of course I do! Objective criticism from an informed customer who has used your product is the greatest gift a product manager can receive. It’s how we get better. Just expect me to take it personally.
2014 was a crazy year. I spent most of the year thinking about client side code while working on the new Azure Portal. I like to use the holiday break as a time to hang out with the family, disconnect from work, and learn about something new. I figured a programming language used for distributed systems was about as far from client side JavaScript as I could get for a few weeks, so I decided to check out golang.
Coming at this from 0 - I used a few resources to get started:
Tour of Go - this was a great getting started guide that walks step by step through the language.
Go by Example - I actually learned more from go by example than the tour. It was great.
The github API wrapper in Go - I figured I should start with some practical code samples written by folks at Google. When in doubt, I used this to make sure I was doing things ‘the go way’.
I’m a learn-by-doing kind of guy - so I decided to learn by building something I’ve built in the past - an API wrapper for the Yelp API. A few years ago, I was working with the ineffable Howard Dierking on a side project to compare RoR to ASP.NET. The project we picked needed to work with the Yelp API - and we noticed the lack of a NuGet package that fit the bill (for the record, there was a gem). To get that project kickstarted, I wrote a C# wrapper over the Yelp API - so I figure, why not do the same for Go? You can see the results of these projects here:
To get a feel for the differences, it’s useful to poke around the two repositories and compare apples to apples. This isn’t a “Why I’m rage quitting .NET and moving to Go” post, or a “Why Go sucks and is doing it wrong” post. Each stack has it’s strengths and weaknesses. Each is better suited for different teams, projects and development cultures. I found myself wanting to understand Go in terms of what I already know about .NET and nodejs, and wishing there was a guide to bridge those gaps. So I guess my goal is to make it easier for those coming from a .NET background to understand Go, and get a feel for how it relates to similar concepts in the .NET world. Here we go!
disclaimer: I’ve been writing C# for 14 years, and Go for 14 days. Please take all judgments of Go with a grain of salt.
Environment Setup
In the .NET world, after you install Visual Studio - you’re really free to set up a project wherever you like. By default, projects are created in ~/Documents, but that’s just a default. When we need to reference another project - you create a project reference in Visual Studio, or you can install a NuGet package. Either way - there really aren’t any restrictions on where the project lives.
Go takes a different approach. If you’re getting started, it’s really important to read/follow this guide:
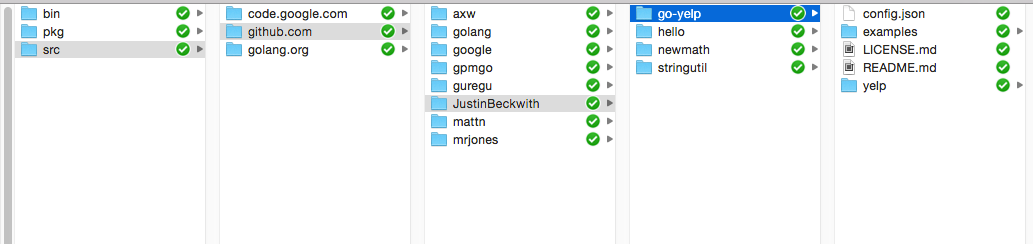
All go code you write goes into a single root directory, which has a directory for each project / namespace. You tell the go tool chain where to find that directory via the $GOPATH environment variable. You can see on my box, I have all of the pieces I’ve written or played around with here:
For a single $GOPATH, you have one set of dependencies, and you keep a single version of the go toolchain. It felt a little uncomfortable, and at times it made me think of the GAC. It’s also pretty similar to Ruby. Ruby has RVM to solve this problem, and Go has GVM. If you’re working on different Go projects that have different requirements for runtime version / dependencies - I’d imagine you want to use GVM. Today, I only have one project - so it is less of a concern.
Build & Runtime
In .NET land we use msbuild for compilation. On my team we use Visual Studio at dev time, and run msbuild via jenkins on our CI server. This is a pretty typical setup. At compile time, C# code is compiled down into IL, which is then just-in-time compiled at runtime to the native assembly language of the system’s host.
Go is a little different, as it compiles directly to native code on the current platform. If I compile my yelp library in OSX, it creates an executable that will run on my current machine. This binary is not interpreted, or IL - it is a good ol’ native executable. When linking occurs, the full native go runtime is embedded in your binary. It has much more of a c++ / gcc kind of feel. I’m sure this doesn’t hurt in the performance department - which is one of the reasons folks move from Python/Ruby/Node to Go.
Compilation of .go files is done by running the go build command from within the directory that contains your go files. I haven’t really come across many projects using complex builds - its usually sufficient to just use go build. Outside of that - it seems like most folks are using makefiles to perform build automation. There’s really no equivalent of a.csproj file, or .sln file in go - so there’s no baked in file you would run through an msbuild equivalent. There are just.go files in a directory, that you run the build tool against. At first I found all of this alarming. After a while - I realized that it mostly “just worked”. It feels very similar to the csproj-less build system of ASP.NET vNext.
Package management
In the .NET world, package management is pretty well known: it’s all about NuGet. You create a project it, add a nuspec, compile a nupkg with binaries, and publish them to nuget.org. There are a lot of NuGet packages that fall under the “must have” category - things like JSON.NET, ELMAH and even ASP.NET MVC. It’s not uncommon to have 30+ packages referenced in your project.
In .NET, we have a packages.config that contains a list of dependencies. This is nice, because it explicitly lays out what we depend upon, and the specific version we want to use:
Go takes a bit of a different approach. The general philosophy of Go seems to trend towards avoiding external dependencies. I’ve found Blake Mizerany’s talk to be pretty standard for sentiment from the community:
In Go - there’s no equivalent of packages.config. It just doesn’t exist. Instead - dependency installation is driven from Git/Hg repositories or local paths. The dependency is installed into your go path with the go get command:
go get github.com/JustinBeckwith/go-yelp/yelp
This command pulls down the relevant sources from the Git/Hg repository, and builds the binaries specific to your OS. To use the dependency, you don’t reference a namespace or dll - you just import the library using the same url used to acquire the library:
When you go compile, the compiler walks through each *.go file, finds the list of external (non BCL) libraries, and implicitly does a go get if needed. This is both awesome and frightening at the same time. It’s great that go doesn’t require explicit dependencies. It’s great that I don’t need to think of the package and the namespace as different entities. It’s not cool that I cannot choose a specific version of a package. No wonder the go community is skeptical of external dependencies - I wouldn’t reference the tip of the master branch of any project and expect it to keep working for the long haul.
To get get around this limitation, a few package managers started to pop up in the community. There are a lot of them. Given the lack of a single winner in this space, I chose to write my package ‘the go way’ and not attempt using a package manager.
Tooling
In the .NET world - Visual Studio is king. I know a lot of folks that use things like JetBrains or SublimeText for code editing (I’m one of those SublimeText folks), but really it’s all about VS. Visual Studio gives us project templates, IntelliSense, builds, tests, refactoring, code outlines - you get it. It’s all in the box. A giant box.
With Go, most developers tend to use a more stripped down code editor. There are a lot of folks using vim, sublimetext, or notepad++. Here are some of the more popular options:
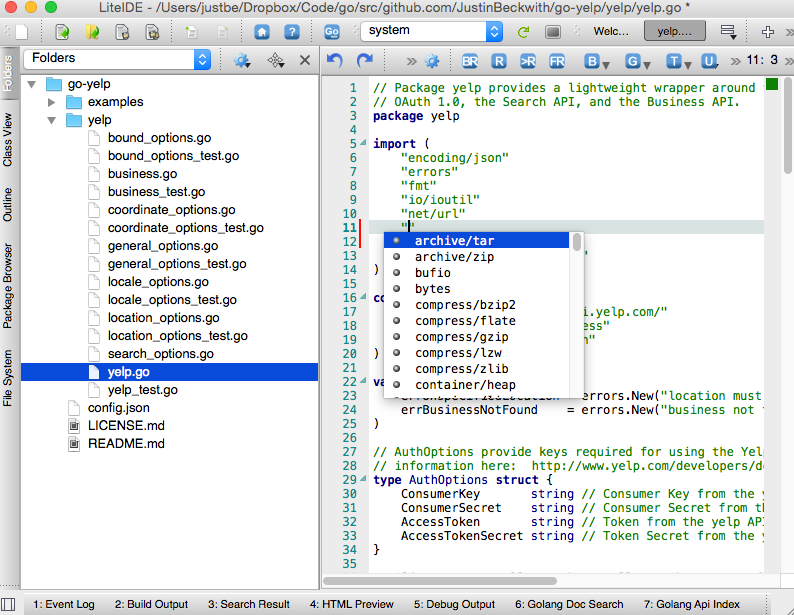
You can find a good conversation about the topic on this reddit thread. Personally - I’m comfortable with SublimeText, so I went with that + the GoSublime plugin. It gave me syntax highlighting, auto-format on save, and some lightweight IntelliSense for core packages. That having been said, LiteIDE feels a little more close to a full featured IDE:
There are a lot of options out there - which is a good thing :) Go comes with a variety of other command line tools that make working with the framework easier:
go build - builds your code
go install - builds the code, and installs it in the $GOPATH
go test - runs all tests in the project
gofmt - formats your source code matching go coding standards
gocov - perform code coverage analysis
I used all of these while working on my library.
Testing
In YelpSharp, I have the typical unit test project included with my package. I have several test files created, each of which has several test functions. I can then run my test through Visual Studio or the test runner. A typical test would look like this:
The accepted pattern in Go for tests is to write a corresponding <filename>_test.go for each Go file. Every method that starts with Test<RestOfFunctionName> in the name, is executed as part of the test suite. By running go test, you run every test in the current project. It’s pretty convenient, though I found myself wishing for something that auto-compiled my code and auto-ran tests (similar to the grunt/mocha/concurrent setup I like to use in node). A typical test function in go would look like this:
// TestGeneralOptions will verify search with location and search term.funcTestGeneralOptions(t*testing.T){client:=getClient(t)options:=SearchOptions{GeneralOptions:&GeneralOptions{Term:"coffee",},LocationOptions:&LocationOptions{Location:"seattle",},}result,err:=client.DoSearch(options)check(t,err)assert(t,len(result.Businesses)>0,containsResults)}
The assert I used here is not baked in - there are no asserts in Go. For code coverage reports, the gocov tool does a nice job. To automatically run test against my GitHub repository, and auto-generate code coverage reports - I’ve using Travis CI and Coveralls.io. I’m planning on writing up another post on the tools you can use to build an effective open source Go library - so more on that later :)
Programming language
Finally, let’s take a look at some code. C# is amazing. It’s been around now for 15 years or so, and it’s grown methodically (in a good way). In terms of basic syntax, it’s your standard C derivative language:
usingSystem;usingSystem.Collections.Generic;usingSystem.Linq;usingSystem.Text;namespaceYelpSharp.Data.Options{/// <summary>/// options for locale/// </summary>publicclassLocaleOptions:BaseOptions{/// <summary>/// ISO 3166-1 alpha-2 country code. Default country to use when parsing the location field./// United States = US, Canada = CA, United Kingdom = GB (not UK)./// </summary>publicstringcc{get;set;}/// <summary>/// ISO 639 language code (default=en). Reviews written in the specified language will be shown./// </summary>publicstringlang{get;set;}/// <summary>/// format the properties for the querystring - bounds is a single querystring parameter/// </summary>/// <returns></returns>publicoverrideDictionary<string,string>GetParameters(){varps=newDictionary<string,string>();if(!String.IsNullOrEmpty(cc))ps.Add("cc",this.cc);if(!String.IsNullOrEmpty(lang))ps.Add("lang",this.lang);returnps;}}}
C# supports both static and dynamic typing, but generally trends towards a static type style. I’ve always appreciated the way C# can appeal to both new and experienced developers. The best part about the language in my opinion has been the steady, thoughtful introduction of new features. Some of the things that happened between C# 1.0 and C# 5.0 (the current version) include:
With Go - I found most language features to be… well… missing. It’s a really basic language - you get interfaces (not the way we know them), maps, slices, arrays, and some primitives. It’s very minimal - and this is by design. I was surprised when I started using go and found a few things missing (in no order):
Generics
Exception handling
Method overloading
Optional parameters
Nullable types
Implementing an interface explicitly
foreach, while, yield, etc
To understand why Go doesn’t have these features - you have to understand the roots of the language. Rob Pike (one of the designers of Go) really explains the problems they were trying to solve, and the design decisions of the language well in his post “Less is exponentially more”. The idea is to provide a set of base primitive constructs: only the ones that are absolutely required.
Interfaces, methods, and not-classes
Having written a lot of C# - I got used to having all of these features at my disposal. I got used to traditional OOP features like classes, inheritance, method overloading, and explicit interfaces. I also write a lot of JavaScript - so I understand (and love) dynamic typing. What’s weird about Go is that is both statically typed - and doesn’t provide many of the OOP features I’ve grown to lean upon.
To see how this plays out - lets look at the same structure written in Go:
packageyelp// LocaleOptions provide additional search options that enable returning results// based on a given country or locale.typeLocaleOptionsstruct{// ISO 3166-1 alpha-2 country code. Default country to use when parsing the location field.// United States = US, Canada = CA, United Kingdom = GB (not UK).ccstring// ISO 639 language code (default=en). Reviews written in the specified language will be shown.langstring}// getParameters will reflect over the values of the given struct, and provide a type appropriate// set of querystring parameters that match the defined values.func(o*LocaleOptions)getParameters()(paramsmap[string]string,errerror){params=make(map[string]string)ifo.cc!=""{params["cc"]=o.cc}ifo.lang!=""{params["lang"]=o.lang}returnparams,nil}
There are a few interesting things to call out from these two samples:
The Go sample and C# are close to the same size - XMLDoc in this case really makes C# seem longer.
I’m not using a class - but rather an interface. Interfaces can support methods via the syntax above. If you define a func that takes a pointer to an object of the interface type - it now supports methods.
In my C# sample, this structure implements an interface. In Go, you write an interface, and then structures implement them ambiently - there is no implements keyword.
Pointers are an important concept in Go. I haven’t had to think about pointers since 2001 (the last time I wrote C++). It’s not a big deal, but not something I expected to run into.
Notice that the getParameters() function returns multiple results - that’s new (and kind of cool).
The getParameters() method returns an error as one of the potential return values. You need to do that since there is no concept of an exception in Go.
Error handling
Let that one sink for a moment. Go takes a strange (but effective) approach to error handling. Instead of tossing an exception and expecting the caller to catch and react, many (if not most) functions will return an error. It’s on the caller to check the value of that error, and choose how to react. You can learn more about error handling in Go here. The net result, is that I wrote a lot of code like this:
// DoSearch performs a complex search with full search options.func(client*Client)DoSearch(optionsSearchOptions)(resultSearchResult,errerror){// get the options from the search providerparams,err:=options.getParameters()iferr!=nil{returnSearchResult{},err}// perform the search requestrawResult,_,err:=client.makeRequest(searchArea,"",params)iferr!=nil{returnSearchResult{},err}// convert the result from jsonerr=json.Unmarshal(rawResult,&result)iferr!=nil{returnSearchResult{},err}returnresult,nil}
In this example, the DoSearch method returns multiple values (get used to this), one of which is an error. There are 3 different method calls made in this function - all of which may return an error. For each of them, you need to check the err value, and choose how to react - oftentimes, just bubbling the error back up through the callstack by hand. I haven’t quite learned to love this aspect of the language yet.
Writing async code
In the previous sample, you may have noticed something fishy. On the following line, I’m making an HTTP request, checking for an error, and them moving forward:
That code is synchronous. When I first wrote this code - I was fairly certain I was making a mistake. Years of callbacks or promises in node, and years of tasks and async/await in C# had taught me something really clear - synchronous methods that block the thread are bad. But here’s Go - just doing it’s thing. I thought I was making a mistake, until I started poking around and found a few people with the same misunderstanding. To make a call asynchronously in Go, it’s largely up to the caller, using a goroutine. Goroutines are kind of cool. You essentially point at a function and say ‘run this asynchronously’:
funcAnnounce(messagestring,delaytime.Duration){gofunc(){time.Sleep(delay)fmt.Println(message)}()// Note the parentheses - must call the function.}
Running go <func> in this manner will run the function concurrently in the same process. This does not create a system thread or fork the process - it’s completely internal to the go runtime. Like most things with Go - I was confused and scared at first, as I tried to apply what I know about C# and JavaScript to their model. I haven’t written enough of this style of asynchronous code to have a great feel for the subject, but I plan to spend a lot of time here in the coming weeks.
What’s next
My experience so far with Go has been at times frustrating, but certainty not boring. The best advice I can give for those new to the language is to let go of your preconceived notion of how [insert concept or task] works - it’s almost like the designers of Go tried to do things differently for the sake of doing it differently at times. And that’s ok :) I was cursing far less at the end of the project than the beginning, and I’ve now started to move towards understanding why it’s different (except for the lack of generics - that’s just weird). It’s helping me question some of the design decisions I’ve made on my own APIs at work, and helped me better appreciate the niceties of C#.
I’ve really only scratched the surface of what’s out there for Go. Now that I’ve put together a library, I’m going to take the next step and start playing around with revel, which provides an ASP.NET style web framework on top of Go. From there, I’m going to keep on building, and see where this goes. Happy coding!
The gopher image is Creative Commons Attributions 3.0 licensed. Credit Renee French.
While attending the developer conference Øredev last week, I had the pleasure of giving a talk on es6. Many of the new features I covered touch on challenges we’ve faced building the Azure Portal. Instead of covering each new feature one by one (Luke Hoban already does a nice job of that) I decided to cover a few high level features that fundamentally affect the way teams build large scale JavaScript applications.
Last week I had the amazing opportunity to give a talk on ASP.NET vNext at the Øredev developer conference. I had a blast - especially the part where I got to show off the new bits to a few hundred people on the big stage. It’s especially fun showing off the new features that open up ASP.NET development with Mono on OSX. There’s a lot of great stuff in this release - the new request pipeline, bin deployable CLR, command line tools, configuration APIs, SublimeText support, fewer dependencies on Visual Studio - and lots of open source.