Analyzing node.js on GitHub with BigQuery

As someone who works on developer tooling - GitHub is the holy grail of data sets. There's just so much code out there, written by so many people, for so many reasons. I've often wished I could just clone all of the data on GitHub, and then write scripts to process the data for various reasons:
- What are the top 1k npm modules used with Node.js apps? We want to know this so we can test them with App Engine.
-
What percentage of people are defining their supported Ruby versions in .ruby-version files? What about Gemfile? Can we reliabily use that to choose a Ruby version for the user?
-
What's the most common way to inject configuration? Environment variables? Nconf? Etcd? Dotenv?
For each of these, we're largely left to poke around using anecodtal observations or surveys. Having a simple way of answering these questions would be huge. Well... using the new public GitHub dataset with BigQuery we can.
BigQuery is essentially a giant data warehouse that lets you store petabytes of data, originally built for internal use at Google. Usually querying over this much data requires a ton of infrastructure and an understanding of MapReduce... but BigQuery lets me just use SQL.
One of the fun things BigQuery offers is a bunch of public data sets. Some of the fun sets include:
I was hanging out with with Sandeep Dinesh at NodeSummit a few weeks ago, and we were chatting about some of the new data available in BigQuery from GitHub. We figured with a little bit of SQL ... we could learn all kinds of cool stuff.
To get started - first, you're going to need to visit the BigQuery console.
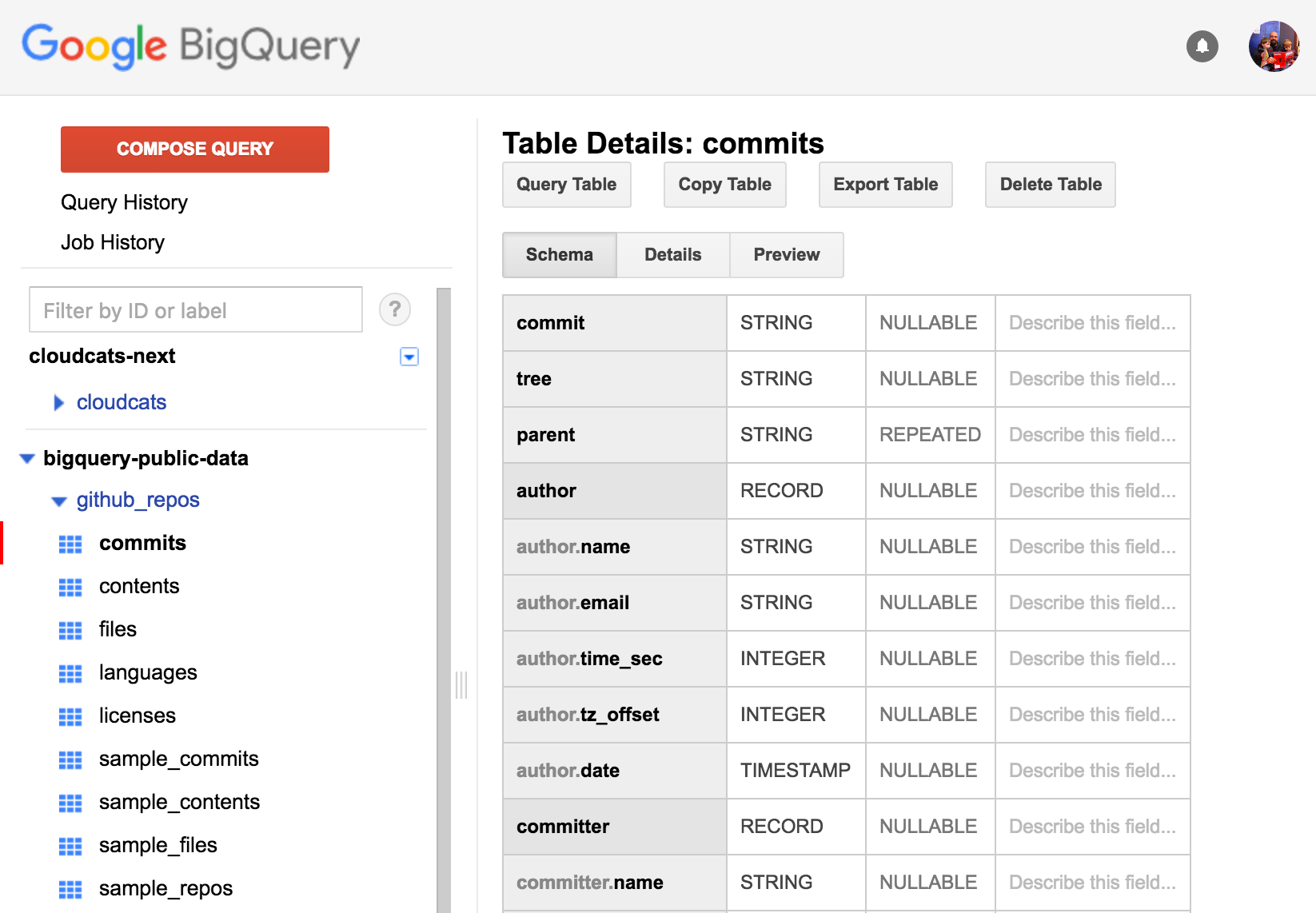
From here we can choose the dataset, and start taking a look at the schema. Now lets start asking some interesting questions!
How many files are out there on GitHub
We just need to query over the github_repos.files table, and get a count.
SELECT COUNT(*) FROM [bigquery-public-data:github_repos.files]
2,122,805,654
Wow -over 2 billion files. Next question!
How many package.json(s) are there on GitHub?
This time we're just going to limit our files to paths ending in package.json. We can just use the RIGHT function to grab the end of the full path:
SELECT COUNT(*) FROM [bigquery-public-data:github_repos.files] WHERE RIGHT(path, 12) = "package.json"
8,128,298
Over 8 million! Now of course - this could include any project that has a package.json (not node.js), so it's probably going to be a little front-end heavy.
What's the most popular top level npm import on GitHub?
So here's the big one. Lets say you want to know which npm module is most likely to be imported as a top level dependency? You could get some of this data by looking at npmjs.com, but that's going to include subdependencies, and also count every install. I don't want every install - I want to know how many apps are using which modules.
Up until this point, we've only been looking at the data available to us directly in the table. But in this case - we want to parse the contents of a file. This is where things start to get fun. This query will...
- Grab all of the
package.jsonfiles out there - Get the contents of those files
- Run a JavaScript user-defined-function
- Place the results in a temp table
- Do a
GROUP BY/ORDER BYto get our final count
Let's take a look!
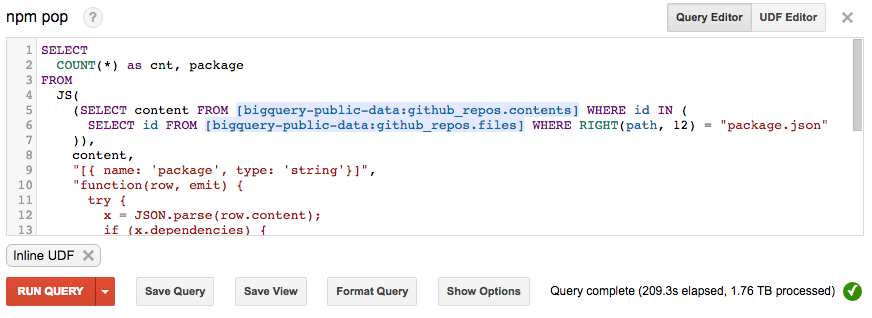
SELECT
COUNT(*) as cnt, package
FROM
JS(
(SELECT content FROM [bigquery-public-data:github_repos.contents] WHERE id IN (
SELECT id FROM [bigquery-public-data:github_repos.files] WHERE RIGHT(path, 12) = "package.json"
)),
content,
"[{ name: 'package', type: 'string'}]",
"function(row, emit) {
try {
x = JSON.parse(row.content);
if (x.dependencies) {
Object.keys(x.dependencies).forEach(function(dep) {
emit({ package: dep });
});
}
} catch (e) {}
}"
)
GROUP BY package
ORDER BY cnt DESC
LIMIT 1000
So this is really freaking cool. We were able to just slam a JavaScript function in the middle of the SQL query to help us process the results. You may also notice the try/catch floating around in there - turns out that not every package.json on GitHub is valid JSON!
So let's take a look at the results:
| Package | Count |
|---|---|
| express | 66207 |
| lodash | 55698 |
| debug | 47499 |
| async | 40054 |
| inherits | 35782 |
| body-parser | 35644 |
| request | 31242 |
| mkdirp | 25941 |
| chalk | 25904 |
| readable-stream | 25015 |
| glob | 24497 |
| underscore | 24151 |
| morgan | 22398 |
| minimatch | 20561 |
| cookie-parser | 19957 |
| react | 19764 |
| through2 | 18488 |
| mongoose | 17992 |
| commander | 17805 |
| jade | 17666 |
| isarray | 16677 |
| minimist | 16518 |
| socket.io | 15675 |
| moment | 15434 |
| graceful-fs | 15198 |
| qs | 14663 |
| object-assign | 14218 |
| jquery | 13709 |
| serve-favicon | 13641 |
| string_decoder | 13597 |
| source-map | 13548 |
| babel-runtime | 13524 |
| rimraf | 13233 |
| gulp-util | 13055 |
| express-session | 13045 |
| core-util-is | 13041 |
| bluebird | 12751 |
| semver | 12722 |
| passport | 12530 |
| q | 11990 |
| colors | 11710 |
| mime | 11627 |
| react-dom | 11560 |
| ejs | 11392 |
| xtend | 11312 |
| node-uuid | 11265 |
| optimist | 11070 |
| gulp | 10934 |
| compression | 10759 |
| once | 10544 |
| mime-types | 10352 |
( ... it keeps going for a while ) At the end of this - we processed quite a bit of data.
Query complete (209.3s elapsed, 1.76 TB processed)
What other types of questions should we ask? I can think of a few that may be interesting:
- Which npm dependencies are the most likely to be out of date?
- How many people are using the
fsnpm module (the one on npmjs.com, not the core module) - How many people are hard coding keys in their JavaScript files?
If you want to play around with the GitHub dataset, check out the getting started tutorial.
If you find the answers to these (or anything else interesting), let me know at @JustinBeckwith!